- Open https://www.anaconda.com/products/individual#download-section with your web browser.
- Download the Anaconda for Windows installer with Python 3. (If you are not sure which version to choose, you probably want the 64-bit Graphical Installer Anaconda3-...-Windows-x86_64.exe)
- Install Python 3 by running the Anaconda Installer, using all of the defaults for installation except make sure to check Add Anaconda to my PATH environment variable.
Data carpentry for oceanographers
Using python to accelerate research and increase reproducibility
Woods Hole Oceanographic Institution
Online
Oct 26 & 27, Nov 2 & 3, 2020
8:30AM to 12:30PM EDT
Instructors: Amber York, Karen Soenen
Helpers: Stace Beaulieu, Audrey Mickle, Joe Futrelle, Arianna Krinos, Brett Longworth, Harriet Alexander, Svenja Ryan, Ivan Lima, Katy Abbot, Ryan Govostes, Stewart Jamieson
General Information
Where: This training will take place online. The instructors will provide you with the information you will need to connect to this meeting.
Audience: This workshop is targeted towards the technical WHOI staff in order to improve project efficiency and build technical skills. It will only be held for 20 people at a time through an online Zoom meeting. Registration is required. Please contact stace@whoi.edu for availability.
Prerequisites: To get the most out of this workshop we suggest that participants are already using python for data analysis at a novice or intermediate level. A strong familiarity with Python syntax and basic constructs such as loops, lists and conditionals (i.e. if statements) is required. Python skills covered will progress from novice to intermediate over the course of the workshop.
When: Four half-day, morning workshops on Mondays and Tuesdays. October 26th and 27th, November 2nd and 3rd. Each day will start at 8:30AM and finish at 12:30PM. Breaks will be included in the schedule.
Requirements: Participants must bring a laptop with a Mac, Linux, or Windows operating system (not a tablet, Chromebook, etc.) that they have administrative privileges on. They should have a few specific software packages installed (listed below).
Accessibility: We are dedicated to providing a positive and accessible learning environment for all. Please notify the instructors in advance of the workshop if you require any accommodations or if there is anything we can do to make this workshop more accessible to you.
Contact: Please email adyork@whoi.edu or ksoenen@whoi.edu for more information.
Workshop sponsorship: DDVPR Technical Staff Training Award
Why take this course?
We'll cover:
- Managing tabular data for analysis and reproducibility
- Improving python skills for data analysis, and visualisation, both for tabular and grdided data
- Introducing collaboration and versioning using github and jupyter notebooks.
Managing tabular data for analysis and reproducibility.
Good data organization is the foundation of any research project. Most researchers have data in spreadsheets, so it’s the place that many research projects start.
We organize data in spreadsheets in the ways that we as humans want to work with the data, but computers require that data be organized in particular ways. In order to use tools that make computation more efficient, such as programming languages like R or Python, we need to structure our data the way that computers need the data. Since this is where most research projects start, this is where we want to start too! The concepts learned here also apply more broadly to other tabular formats (e.g. csv and tsv).
In this lesson, you will learn:
- Good data entry practices - formatting data tables in spreadsheets
- How to avoid common formatting mistakes
- Approaches for handling dates in spreadsheets
- Basic quality control and data manipulation in spreadsheets
- Exporting data from spreadsheets
Improving python skills for data analysis and visualization.
Python is rapidly emerging as the programming language of choice for data analysis in the atmosphere and ocean sciences. By consulting online tutorials and help pages, most researchers in this community are able to pick up the basic syntax and programming constructs (e.g. loops, lists and conditionals). This self-taught knowledge is sufficient to get work done, but it often involves spending hours to do things that should take minutes, reinventing a lot of wheels, and a nagging uncertainty at the end of it all regarding the reliability and reproducibility of the results. To help address these issues, these Data Carpentry lessons cover a suite of programming and data management best practices that aren’t so easy to glean from a quick Google search.
Introducing collaboration and versioning using github and jupyter notebooks.
We will be taking this to a next level, introducing tools to increase collaboration, ensure code provenance and lower mistakes with documentation, and use versioning to not save a thousand copies of your code.
About Data Carpentries
Data Carpentry develops and teaches workshops on the fundamental data skills needed to conduct research. Its lessons are domain specific, building on learners' existing knowledge to enable them to quickly apply skills learned to their own research. Participants will be encouraged to help one another and to apply what they have learned to their own research problems.
For more information on what we teach and why, please see our paper "Good Enough Practices for Scientific Computing".
Code of Conduct
Everyone who participates in Carpentries activities is required to conform to the Code of Conduct. This document also outlines how to report an incident if needed.
Surveys
Please be sure to complete these surveys before and after the workshop.
Syllabus
This workshop is based on a few workshops developed by the Carpentries (See https://carpentries.org for more information about the Carpentries organisation.)
- Data Organization in Spreadsheets for Ecologists
- Data Analysis and Visualization for Ecologists
- Python for atmosphere and ocean scientists
Schedule
Day 1. Spreadsheets and Intro to Python & Pandas
Day 2. Visualisation with Python & Libraries
| 08:30 | Refresher | |
| 09:00 | Subsetting Data | From Data Analysis and Visualizaton in Python for Ecologists |
| 09:30 | Combining Data Frames | From Data Analysis and Visualizaton in Python for Ecologists |
| 10:00 | Break | |
| 10:10 | Exercise: Combining Data Frames | |
| 10:30 | Libraries & Software Installation using Conda | From Python for Atmosphere and Ocean Scientists |
| 11:00 | Break | |
| 11:10 | Data Visualisation: Matplotlib | From Data Analysis and Visualizaton in Python for Ecologists |
| 12:00 | Data Visualisation: Plotnine | From Data Analysis and Visualizaton in Python for Ecologists |
| 12:30 | Minute Card - Day 2 |
Day 3. Python Workflows & Gridded data
Day 4. Good Programming Practices
Setup for Week 1 (Days 1 and 2)
To participate in a Data Carpentry workshop, you will need access to the software described below (Zoom, Python, Jupyter notebooks). In addition you will need an up-to-date web browser and access access to a spreadsheet program (Excel, LibreOffice,...),
We maintain a list of common issues that occur during installation as a reference for instructors that may be useful on the Configuration Problems and Solutions wiki page.
Install the videoconferencing client
If you haven't used Zoom before, go to the official website to download and install the Zoom client for your computer.
Set up your workspace
Like other Carpentries workshops, you will be learning by "coding along" with the Instructors. To do this, you will need to have both the window for the tool you will be learning about (a terminal, RStudio, your web browser, etc..) and the window for the Zoom video conference client open. In order to see both at once, we recommend using one of the following set up options:
- Two monitors: If you have two monitors, plan to have your terminal up on one monitor and the video conferencing software on the other.
- Two devices: If you don't have two monitors, do you have another device (tablet, smartphone) with a medium to large sized screen? If so, try using the smaller device as your video conference connection and your larger device (laptop or desktop) to follow along with the tool you will be learning about.
- Divide your screen: If you only have one device and one screen, practice having two windows (the video conference program and one of the tools you will be using at the workshop) open together. How can you best fit both on your screen? Will it work better for you to toggle between them using a keyboard shortcut? Try it out in advance to decide what will work best for you.
Python
Python is a popular language for research computing, and great for general-purpose programming as well. Installing all of its research packages individually can be a bit difficult, so we recommend Anaconda, an all-in-one installer. Please make sure you install Python version 3.x (e.g., 3.6 is fine).
We will teach Python using the Jupyter Notebook, a programming environment that runs in a web browser (Jupyter Notebook will be installed by Anaconda). For this to work you will need a reasonably up-to-date browser. The current versions of the Chrome, Safari and Firefox browsers are all supported (some older browsers, including Internet Explorer version 9 and below, are not).
- Open https://www.anaconda.com/products/individual#download-section with your web browser.
- Download the Anaconda Installer with Python 3 for macOS (you can either use the Graphical or the Command Line Installer).
- Install Python 3 by running the Anaconda Installer using all of the defaults for installation.
Video Tutorial
- Open https://www.anaconda.com/products/individual#download-section with your web browser.
- Download the Anaconda Installer with Python 3 for Linux.
(The installation requires using the shell. If you aren't comfortable doing the installation yourself stop here and request help at the workshop.) - Open a terminal window and navigate to the directory where the executable is downloaded (e.g., `cd ~/Downloads`).
-
Type
bash Anaconda3-
and then press Tab to autocomplete the full file name. The name of file you just downloaded should appear. -
Press Enter
(or Return depending on your keyboard).
You will follow the text-only prompts.
To move through the text, press Spacebar.
Type
yesand press enter to approve the license. Press Enter (or Return) to approve the default location for the files. Typeyesand press Enter (or Return) to prepend Anaconda to yourPATH(this makes the Anaconda distribution the default Python). - Close the terminal window.
Setup for Week 2 (Days 3 and 4)
The Bash Shell
Bash is a commonly-used shell that gives you the power to do tasks more quickly.
- Download the Git for Windows installer.
- Run the installer and follow the steps below:
- Click on "Next" four times (two times if you've previously installed Git). You don't need to change anything in the Information, location, components, and start menu screens.
- From the dropdown menu select "Use the nano editor by default" and click on "Next".
- Ensure that "Git from the command line and also from 3rd-party software" is selected and click on "Next". (If you don't do this Git Bash will not work properly, requiring you to remove the Git Bash installation, re-run the installer and to select the "Git from the command line and also from 3rd-party software" option.)
- Ensure that "Use the native Windows Secure Channel library" is selected and click on "Next".
- Ensure that "Checkout Windows-style, commit Unix-style line endings" is selected and click on "Next".
- Ensure that "Use Windows' default console window" is selected and click on "Next".
- Ensure that "Default (fast-forward or merge) is selected and click "Next"
- Ensure that "Enable file system caching" and "Enable Git Credential Manager" are selected and click on "Next".
- Click on "Install".
- Click on "Finish" or "Next".
-
If your "HOME" environment variable is not set (or you don't know what this is):
- Open command prompt (Open Start Menu then type
cmdand press Enter) -
Type the following line into the command prompt window exactly as shown:
setx HOME "%USERPROFILE%" - Press Enter, you should see
SUCCESS: Specified value was saved. - Quit command prompt by typing
exitthen pressing Enter
- Open command prompt (Open Start Menu then type
This will provide you with both Git and Bash in the Git Bash program.
Video Tutorial
The default shell in some versions of macOS is Bash, and
Bash is available in all versions, so no need to install anything.
You access Bash from the Terminal (found in
/Applications/Utilities).
See the Git installation video tutorial
for an example on how to open the Terminal.
You may want to keep Terminal in your dock for this workshop.
To see if your default shell is Bash type echo $SHELL
in Terminal and press the Return key. If the message
printed does not end with '/bash' then your default is something
else and you can run Bash by typing bash
If you want to change your default shell, see this Apple Support article and follow the instructions on "How to change your default shell".
Video Tutorial
The default shell is usually Bash and there is usually no need to install anything.
To see if your default shell is Bash type echo $SHELL in
a terminal and press the Enter key. If the message printed
does not end with '/bash' then your default is something else and you
can run Bash by typing bash.
Git
Git is a version control system that lets you track who made changes to what when and has options for easily updating a shared or public version of your code on github.com. You will need a supported web browser.
You will need an account at github.com for parts of the Git lesson. Basic GitHub accounts are free. We encourage you to create a GitHub account if you don't have one already. Please consider what personal information you'd like to reveal. For example, you may want to review these instructions for keeping your email address private provided at GitHub.
Git should be installed on your computer as part of your Bash install (see the Shell installation instructions).
For macOS, install Git for Mac
by downloading and running the most recent "mavericks" installer from
this list.
Because this installer is not signed by the developer, you may have to
right click (control click) on the .pkg file, click Open, and click
Open on the pop up window.
After installing Git, there will not be anything in your /Applications folder,
as Git is a command line program.
For older versions of OS X (10.5-10.8) use the
most recent available installer labelled "snow-leopard"
available here.
Video Tutorial
If Git is not already available on your machine you can try to
install it via your distro's package manager. For Debian/Ubuntu run
sudo apt-get install git and for Fedora run
sudo dnf install git.
Installing required packages
For the workshop we recommend installing the required packages using the Anaconda Prompt in windows (or Terminal in Mac/Linux) as described in method 1 (below). If you try method 2 and that does not work for you, you can try method 1 at any time since it uses a separate environment we create just for this lesson.
Install method 1: Make a new environment and launch jupyter notebooks using the new environment.
This method is more fail-safe than method 2. As shown in the steps below you have to use a command line (Anaconda Prompt(win) Terminal(Mac/Linux) to launch jupyter notebook, not the graphical Anaconda Navigator.
Steps- Open Anaconda Prompt (Windows) or Terminal(Mac/Linux)
-
Enter the following command to create a new environment called "pyaos-lesson"
conda create -n pyaos-lesson -c conda-forge jupyter xarray netCDF4 cartopy cmocean cmdline_provenance plotnine -
You will be asked if you would like to install the packages after they are found. Press Yes (y).
You should see messages for Preparing, Verifying, and Executing the "transaction" and end with a line that says "done"
-
Enter the new environment you created. After this command you should see "(pyaos-lesson)" at the start of your line.
conda activate pyaos-lesson -
Launch the jupyter notebook with the following command. A new browser window should pop up with jupyter notebook in it.
jupyter notebook - Test your installs worked. See "Testing Your Installs" section Below.
Install Method 2: Using the base environment
This method may be quite slow for some people and you may encounter more issues than method 1. But if you have completed your installs with this method and your test works then you are all set for the worksohp (See "Testing Your Installs" section Below).
Steps- Enter
conda activate baseand press enter to execute. This makes sure you are in your base environment. It won't hurt anything if you already are in base and run it anyway. You should see "(base)" at the beginning of your line. -
Run the following commands one at a time. It may take a few minutes to respond during this process. You will be asked if you would like to install the packages after they are found. Press Yes (y).
conda install jupyter xarray netCDF4 cartopyconda install -c conda-forge cmocean cmdline_provenance plotnineYou should see messages for Preparing, Verifying, and Executing the "transaction" and end with a line that says "done"
- Launch the jupyter nootebook using either Anaconda Navigator or command line using Anaconda Prompt(Windows) or Terminal(Mac/Linux).
- Test your installs worked. See "Testing Your Installs" section Below.
Testing your installs
To check your install was successful and you can use the packages within a notebook, you can enter the following into a jupyter notebook cell and run it. You should be able to execute the cell without an error. It may take a few seconds then will show you "Hello World!" after the cell.
import xarray as xr
import cartopy.crs as ccrs
import matplotlib.pyplot as plt
import numpy as np
import cmocean
import cmdline_provenance as cmdprov
import plotnine as p9
import pandas as pd
print("Hello World!")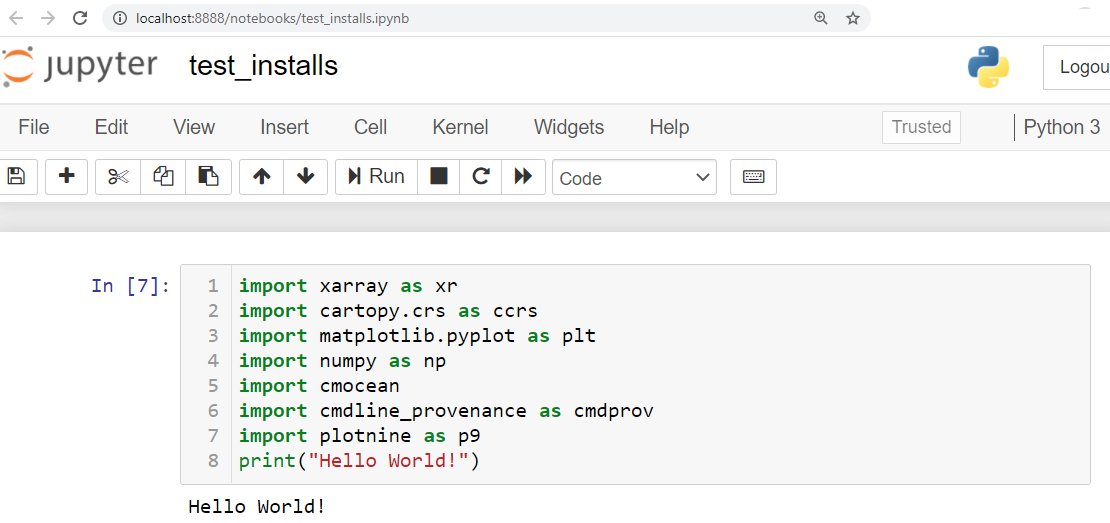
Launching Jupyter Notebook
*if you have just followed the instructions to install packages and test them, you already have launched jupyter notebook and can use that. You can follow these instructions if you don't already have a notebook running.
Steps- Open an Anaconda Prompt(Win) or Terminal(Mac/Linux).
-
Enter the environment wish to use. After this command you should see the environment name "(pyaos-lesson)" or "base" at the start of your line.
If you installed your packages using method 1:
conda activate pyaos-lessonIf you installed your packages using method 2:
conda activate base -
Launch the jupyter notebook with the following command. A new browser window should pop up right into your notebook.
jupyter notebookA browser window will open with your notebook in it. If you close the page and need to get back to it, you can copy and paste the link shown in your Anaconda Prompt/Terminal. Or you can try the default address http://localhost:8888/.
For a brief introduction to Jupyter Notebooks, please consult our Introduction to Jupyter Notebooks page. If you installed your required packages using method 2, you can also launch jupyter notebook using the Anaconda Navigator (instead of command line) as shown in that lesson.
Data
In preparation for these lessons,you will need to download the following two Python scripts and four netCDF files and place them in a new folder/directory:
- Make a new folder in your Desktop called `data-carpentry` if you haven't already.
- Download script_template.py and plot_precipitation_climatology.py and move them into that folder.
- Make a new folder in your `data-carpentry` folder called `data` if you haven't already.
- Download the following files and place them in that folder: